

クローラーは、インターネット上でWebサイトを巡回して、ページの情報を収集します。検索エンジンは、その収集した情報を元に検索順位を表示します。
つまりSEO対策の基本として、検索エンジンのクローラーが正しく巡回してもらうことは必須です。
この記事では、クローラーについてと巡回する流れを解説します。
クローラーとは
クローラーは、インターネット上にあるWebサイトを探しまわり、コンテンツを収集するシステムのことです。googleやBingなどの検索エンジンは、それぞれのクローラーを持っていて取得したコンテンツを整理した上で検索結果に表示します。
サイト内を回遊しやすいように、サイト内の構造を適切に整えることを「クローラビリティ」といいます。
クローラビリティを向上させることでSEO効果になります。
クローラーがWebサイトを巡回する仕組み
リンクから巡回
クローラーは、外部リンクを辿って巡回してきます。Googleのクローラーは、インターネット上にあるWebサイトやSNSのリンクから、さらにSNSのリンクを辿り別のWebサイトの存在を把握して、情報を取得します。
内部リンクや外部リンクなどが多い記事ほど、クローラーの入り口が増えるということです。
依頼されたURLを巡回
新しく作ったサイトには巡回がすぐに来てはくれないので、自ら申請を出す必要があります。
その申請を出す方法を紹介します。
URL検査ツールから「インデックス登録をリクエスト」する
- サーチコンソールにログインし、メニューの「URL検索」をクリック
- 上部のURL検索窓から巡回してほしいページのURLを貼り付ける
- 入力したページのインデックス登録状況が表示される
- そこに表示されている「インデックス登録をリクエスト」のボタンをクリックで申請完了
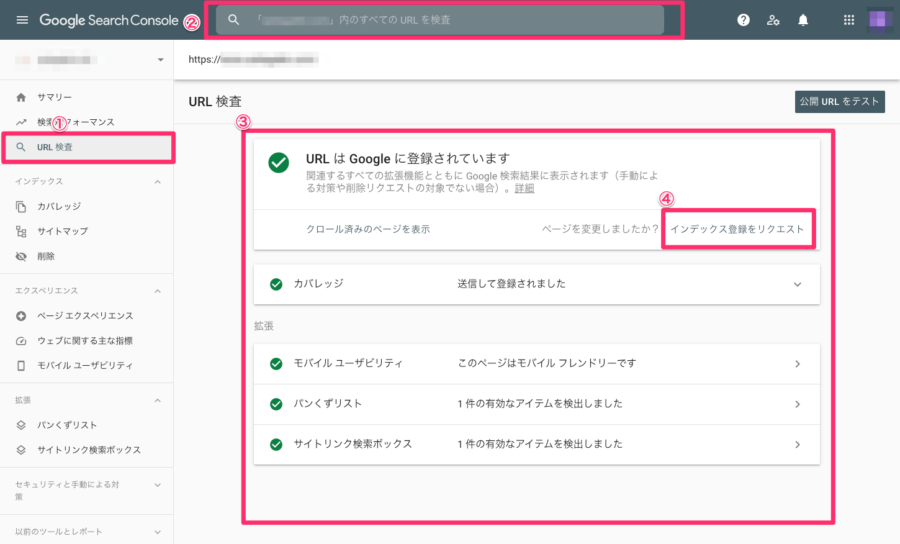
すでにインデックス登録している既存のページだけでなく、まだ、インデックスしていない新規のページも同様にインデックスを促すことができます。
XMLサイトマップを送信する
XMLサイトマップのURLをGoogleサーチコンソールに送信することで、Googleのクローラーに伝えることが可能です。
- サーチコンソールにログインし、メニューの「インデックス」から「サイトマップ」をクリック
- 「新しいサイトマップの追加」からすでに本番環境へとアップロード済みのXMLサイトマップのURLを記述
- 最後に、送信ボタンをクリック
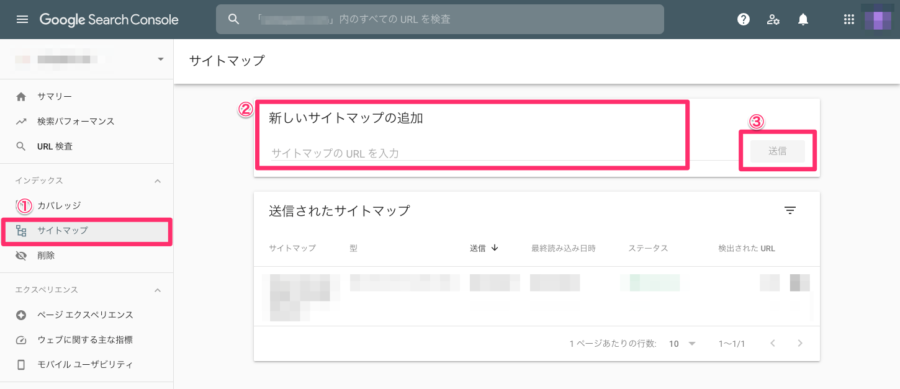
※XMLサイトマップを作成していないと、ファイルを送信することが出来ません。
クローラーのサイト内の動き
クローラーが実際にWebサイトをどのように巡回しているか、仕組みについて見ていきます。
クローラーが取得する情報
クローラーは、次のようなファイルを取得して巡回します。
- HTML
- CSS
- JavaScript
- 画像(GIF/JPEG/PNG/WebP/SVG)
- 動画(MP4/WebMなど)
- オフィス文書(Word/Excel/PowerPoint)
HTMLのテキストはもちろん、画像や動画などの情報も取得します。
取得した情報を解析
HTMLに画像の記述が下記のようにあった場合、クローラーはalt属性を理解してくれるので、この画像を「web制作会社」というテキストと等価であると解析処理を行います。
<img src="http://” alt=”web制作会社”>
titleタグでも同じようにtitleタグに囲まれている部分は、そのページのタイトルと解析処理します。
HTMLのみではなく、各種メディアファイルも取得していますので、画像ファイルは画像検索、動画ファイルは動画検索に表示されます。WordファイルやPDFファイルも検索結果に表示されます。
リンクをたどる
Web上のリンクを辿って巡回してきます。Webサイトにはいくつものページが連なっていますが、そのすべてのリンクを自動で巡回していきます。具体的にはaタグに記載されたリンク先ページを次々と巡回します。
なので、パンくずリストのような内部リンクは、評価を上げる施策となります。
なお、クローラーが辿れるのはリンクのみで、ログインが必要なページは巡回することができません。
まとめ
クローラーからいい評価をを受けれるように、良いコンテンツを作れることを心がけましょう。



